
OpenAI Bot
General
GPT chatbot is available on chats. If you turn it on, all users will be able to apply to it anytime with any questions. You can set it up through the admin panel.
All data about the requests to the bot are gathered on the dashboard.
How does it work for users?
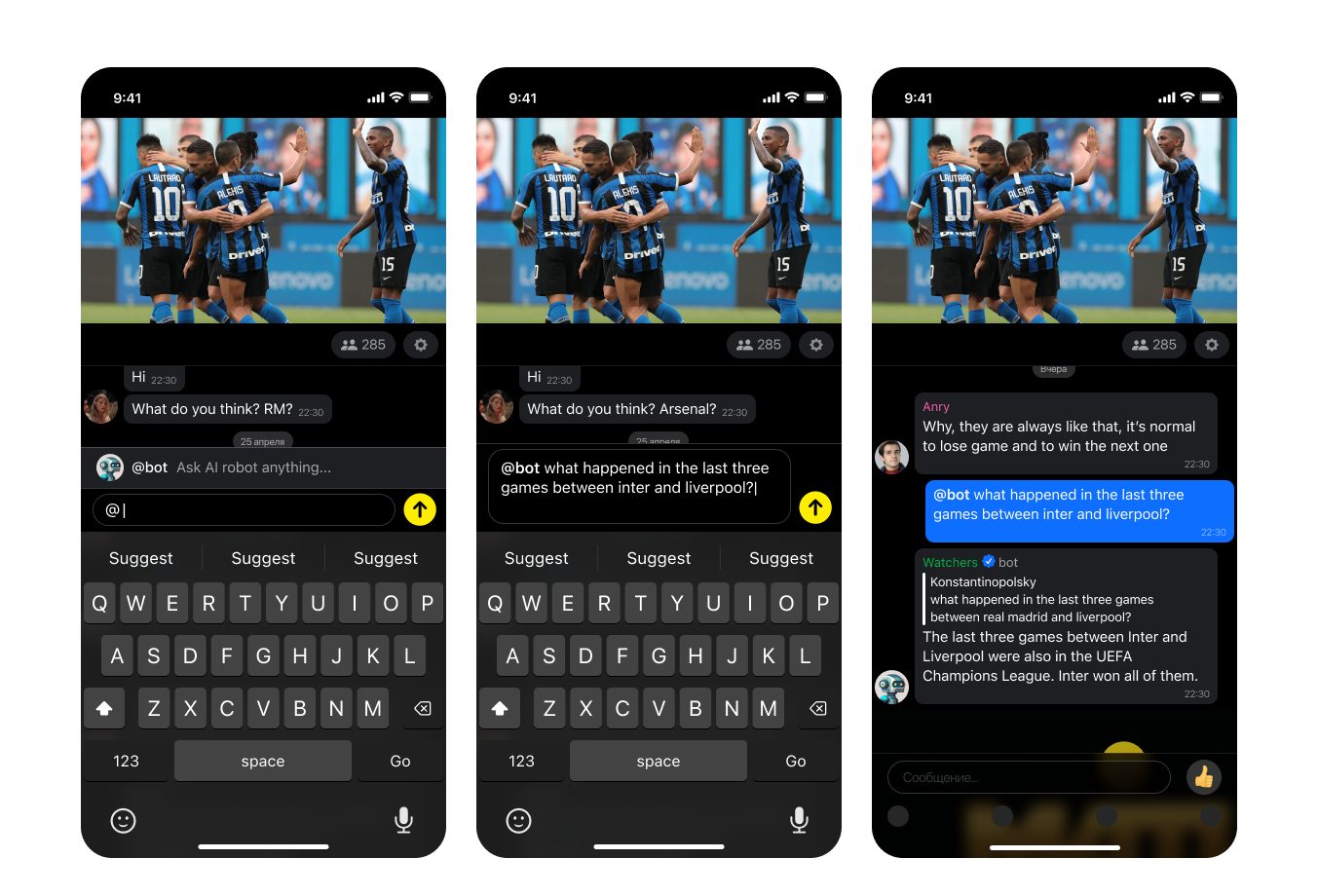
Users apply a GPT bot through the request sent via input (the bot’s name is set through the admin panel). After typing @-character, users see the suggestion to apply a bot. After typing the bot name, users have to type a request.
All requests are checked with moderation systems. If the request is acceptable, users get the bot’s answer linked to the request. After sending the first request, a user sees the disclaimer that the bot is based on AI and doesn’t guarantee the correct information based on truthful sources. If the moderation system stops a user’s request, the user gets an alert that their message was declined because of breaking chat rules.
Roles: regular users, speakers, admins, and moderators can apply to the bot.
Managing the bot through the admin panel
The bot can be turned on through the admin panel (Settings/ ChatGPT Settings, switch it to enable). Here you can change the bot’s name and upload an avatar.
openai.api_key: This field stores the unique API key associated with your OpenAI account. The API key is required for authentication purposes when making requests to OpenAI's API.
Also, you can set parameters for the bot’s working:
- Temperature controls the “creativity” or randomness of the generated text. A higher value (e.g., 1.0) results in more diverse and creative responses, while a lower value (e.g., 0.4) leads to more focused and deterministic outputs. Adjusting this parameter can help you find the right balance between creativity and consistency in the generated text.
- Max tokens determine the maximum length of the generated text. By limiting the output length, you can prevent excessively long responses and control the verbosity of the model.
- top_p: this parameter sets the probability threshold for token selection. The model will only consider tokens with a cumulative probability less than or equal to top_p for sampling. A value of 1.0 means all tokens are considered, while a lower value (e.g., 0.9) results in a more focused and deterministic output by excluding low-probability tokens.
- Frequency penalty: the parameter controls the model's tendency to repeat predictions. A value of 0.0 means no penalty is applied, while a positive value (e.g., 1.0) encourages the model to use less frequent tokens, potentially resulting in more diverse and creative responses.
- Presence penalty: this parameter encourages the bot to make novel predictions. A value of 0.0 means no penalty is applied, while a higher value (e.g., 0.4) encourages the model to use a greater variety of tokens and avoid repeating the same phrases or terms.
Cases
- Editing the request
If users edit the message to the bot, the request isn't sent for the second time.
- Deleting the request
If users delete the message before the request is sent, this request is cancelled. If the request is sent and then the user deletes the message, the bot's answer won't be published. If the user deletes the message after publishing the bot's answer, this answer stays in the chat.
- Bans of the users who sent requests to the bot
The bot's answer doesn't appear in the chat if the user who sent the request is banned in a room or an app.
- Moderation on the Open AI side
If the Open Ai moderation says that the request is not allowed, the bot's answer contains the alert that the user's request breaks the chat rules.
Updated about 1 month ago